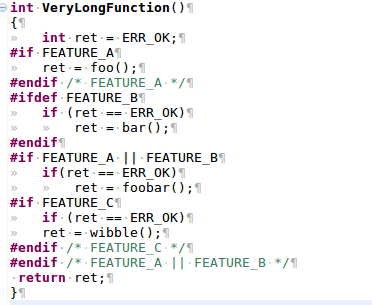
Recently I was training a team in Clean Code for Embedded Systems. The team were very keen to define a coding standard, but as we talked, it became increasingly clear they were more interested in what I would call a coding style. Let me start with a couple of definitions that I use Code Style:...